Der Umgang mit der Komplexität riesiger und vielfältiger Datensätze, die über mehrere Standorte und Formate verstreut sind, stellt heute für viele Unternehmen eine Hürde dar. An der Schnittstelle von Innovation und Praktikabilität erweist sich unsere umfassende Big-Data-Lösung als Schlüssel zur Bewältigung dieser Herausforderungen. Basierend auf unserem umfangreichen Fachwissen bei der Entwicklung erfolgreicher Big-Data-Projekte haben wir eine Lösung entwickelt, die darauf ausgelegt ist, die Fähigkeiten Ihres Unternehmens beim Datenzugriff und bei der Datenverarbeitung nahtlos zu verbessern.
NUTZEN SIE DIE MACHT VON BIG DATA
Daten sind heute die Grundlage des Geschäftsbetriebs. Deshalb ist es so wichtig, die gesammelten Informationen kompetent und effektiv zu erfassen, zu verarbeiten und anschließend zu nutzen. Unsere innovative Big-Data-Lösung stellt Ihrem Unternehmen die Tools zur Verfügung, die es benötigt, um das volle Potenzial Ihrer Daten auszuschöpfen, unabhängig von deren Umfang oder Format.
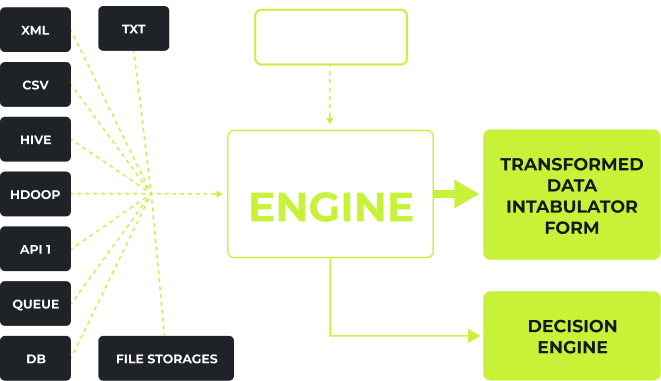
Die Engine von Codespheric unterstützt verschiedene Standardformate, was Zeit spart and und Kosten senkt.
Unsere bewährte, sofort umsetzbare Lösung garantiert die Skalierbarkeit von Projekten.
Die benutzerfreundliche Oberfläche ermöglicht es auch Personen ohne fortgeschrittene IT-Kenntnisse, effizient mit Daten zu arbeiten.
BIG DATA BEI CODESPHERIC
Betreten Sie die Zukunft des Datenmanagements mit unserer hochmodernen Lösung – einem Game-Changer, der Ihre Herangehensweise an unterschiedliche Datenlandschaften revolutionieren soll. Tauchen Sie ein in das Codespheric-Erlebnis, wo Herausforderungen Innovationen auslösen und Lösungen den Weg für beispiellose Möglichkeiten ebnen.
Einheitliche Datenintegration: Nahtlose Integration von Daten aus verschiedenen Quellen und Formaten durch unsere fortschrittliche Datenverwaltungs-Engine.
Effiziente Datenverarbeitung: Optimierte Datenverarbeitung durch eine benutzerfreundliche Oberfläche mit SQL-ähnlichen Abfragen für mehr Effizienz.
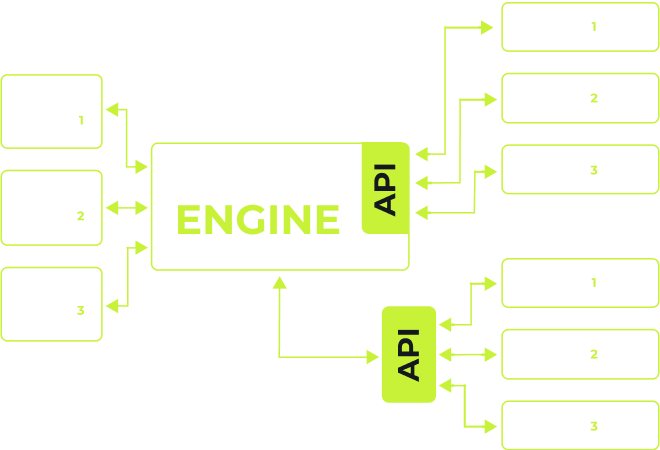
Nahtlose Systemintegration: Effiziente Integration mit externen Systemen, erleichtert durch umfassende API-Steuerung.
Vielseitige Datenaggregation: Die Codespheric-Engine bietet die Flexibilität, als dynamischer Datenaggregator für die nahtlose Integration in andere Lösungen zu dienen.
WARUM BIG DATA WÄHLEN?
Erhebliche Verkürzung der Projektdauer
Kosteneinsparungen für das Projekt
Verbesserte Skalierbarkeit der Lösung
Verbesserte Datenqualität
Flexibilität zur Anpassung und Erweiterung der Lösung
Unser Big-Data-Team arbeitete an der Verbesserung von Geschäftsprozessen und führte eine neue Möglichkeit ein, das Produktangebot des Unternehmens an die Erwartungen der Kunden anzupassen. Mit dieser speziellen Lösung können Sie äußerst zielgerichtete und personalisierte Werbekampagnen starten und so deren Wirksamkeit steigern und gleichzeitig die Kosten optimieren.
Dank dieser Implementierung kann der Kunde Produkte einfach an die Kundenerwartungen anpassen und sie gezielt an Benutzer mit hohem Kaufpotenzial ausrichten.
WICHTIGE SYSTEMANFORDERUNGEN:
Tägliche Verarbeitung von Terabytes an Daten
Lineare Skalierbarkeit
Einheitliche Architektur für unterschiedliche Geschäftsbereiche
TECHNOLOGIE-STACK:
Scala
Spark
Hadoop
Flume
Slick
Diese Zusammenarbeit hat es unserem Kunden ermöglicht, den Produktkatalog besser an die individuellen Vorlieben der Kunden anzupassen. Dies gelang insbesondere durch die Echtzeitverbreitung verschiedener Daten.
2.ECHTZEIT-AUKTIONSMASCHINE
Unsere Zusammenarbeit umfasste den Entwurf und die Erstellung einer fortschrittlichen Echtzeit-Auktionsplattform. Mithilfe eines innovativen Gebotssystems werden Auktionen live online übertragen, sodass angemeldete Teilnehmer in Echtzeit Gebote abgeben können. Diese dynamische Plattform zeichnet sich durch eine bemerkenswerte Reaktionsleistung aus und gewährleistet eine Latenz von nicht mehr als 50 ms.
WICHTIGE SYSTEMANFORDERUNGEN:
20 000 Anfragen pro Sekunde und Server
Lineare Skalierbarkeit
Schnelle Reaktionszeit (<50 ms)
TECHNOLOGIE-STACK:
Scala
Akka
Spray
Aerospike
Slick
Das Ergebnis dieses Projekts war eine hochmoderne Engine für eine Auktionsplattform, die den anspruchsvollen Erwartungen an die Verarbeitung großer Mengen gleichzeitiger Auktionen in Echtzeit gerecht wurde.
3.ENGINE ZUR BERECHNUNG DES BANKRISIKOS
In unserem gemeinsamen Bemühen, das Bankgeschäft zu verbessern, haben wir bei der Implementierung einer neuen Risikoberechnungs-Engine geholfen. Diese Umsetzung trug dazu bei, bessere strategische Entscheidungen zu treffen. Da wir die wachsende Verfügbarkeit und Vielfalt von Statistiken erkannt haben, haben wir Big-Data-Analysen genutzt, um fortschrittliche Modelle zur Visualisierung von Risikomanagementdaten zu entwickeln.
Unser Team spielte eine entscheidende Rolle bei der Architektur und Entwicklung der Lösung im Einklang mit den Analysemodellen der Finanzexperten. Das Ergebnis war ein transformatives System, das die Berechnungszeit erheblich verkürzte, von etwa 18 Stunden auf nur wenige Minuten.
WICHTIGE SYSTEMANFORDERUNGEN:
Tägliche Verarbeitung von Terabytes an Daten
Lineare Skalierbarkeit
Einheitliche Architektur für mehrere Geschäftsbereiche
TECHNOLOGIE-STACK:
Scala
Spark
Hadoop
Flume
Slick
Dieses Projekt leitete eine transformative Ära für diese führende Geschäftsbank ein und ermöglichte es unserem Kunden, in einem Bruchteil der zuvor benötigten Zeit intelligentere Strategien zur Risikominderung umzusetzen und präzisere strategische Entscheidungen zu treffen.
4.DSGVO-VERORDNUNG IN EINEM BIG-DATA-ÖKOSYSTEM EINER BANK
Im Mittelpunkt unserer Zusammenarbeit mit einer führenden Geschäftsbank stand die Umsetzung der Grundprinzipien der Datenschutz-Grundverordnung (DSGVO), die darauf abzielt, Verbrauchern mehr Kontrolle über ihre von Unternehmen erfassten personenbezogenen Daten zu geben. Unser Team half bei der Durchsetzung von Beschränkungen und Regeln für die Dauer der Aufbewahrung von Kundeninformationen.
Um sicherzustellen, dass unsere Kunden diese Vorschriften einhalten, haben wir eine einheitliche Lösung für die Speicherung von Big Data eingeführt. Das Hauptziel dieser innovativen Lösung bestand darin, verschiedene Anwendungen zu integrieren und den Prozess der Verwaltung von Benutzerdaten aus verschiedenen Quellen zu rationalisieren.
WICHTIGE SYSTEMANFORDERUNGEN:
Durchführung von Such- und Löschvorgängen in Terabytes an Daten
Bearbeitung von Tausenden an Anfragen pro Stunde
Hohe Zuverlässigkeit
TECHNOLOGIE-STACK:
Java
Scala
Hadoop
HBase
Hive
Diese Zusammenarbeit führte zu einem robusten System, das die strengen Anforderungen der DSGVO erfüllte und den Kunden der Bank ein Gefühl der Sicherheit hinsichtlich der Benutzerdatenverwaltung gab.
Sie wünschen weitere Informationen oder benötigen Unterstützung
von unseren Spezialisten?